My (Positive) Review of Stanford CS336: Language Modeling from Scratch
I have just conferred my CSBS degree from Stanford and will be doing my coterminal masters next year. My favorite class in the past quarter (& one of my favorites in the past 3 years) was CS336: Language Modeling from Scratch, and this will be my personal review of the class.
General Information (Spring 2025)
taught by: Tatsunori Hashimoto, Percy Liang
2025 video recording (Stanford Online): https://www.youtube.com/playlist?list=PLoROMvodv4rOY23Y0BoGoBGgQ1zmU_MT_
communication: Slack (not EdSTEM)
Median Hours: 27.5 (for 3-5 units)
Enrollment required an application. I was initially on the waitlist and got off on the first day of lecture. The class capacity was 90, and there were 68 enrolled in the end.
Grade Distribution, Student Breakdown
Neither is really available. I asked in the course Slack and 4 A+s were given out in the end for best leaderboard & coursework. I only got an A, though overall I think I did quite well and got a congratulatory email from Percy in the end asking me if I’d be interested to work on Marin :)
Most of the enrolled were definitely grad students, though there are a number of us undergrads, and many auditors.
General Experience
I really like “from the ground up” type classes. My other favorite CS class at Stanford was CS107E: Computer Systems from the Ground Up, which I took the last time it was taught by Pat Hanrahan (using a Raspberry Pi A+, since then it has migrated from ARM to RISC-V and a different board).
This sort of experience just seems to work for me. Even though you can always follow a course and grok it out by yourself, I think the benefit of doing it in a school setting are
you have to move fast, meet major milestones, and wrap up
you get more avenues of help and feedback other than looking at the solution / reference implementation when stuck (can’t learn well when rewards are sparse)
(for this class specifically) you get the hardware / compute
This class had all of that and turned out as nice as I hoped for.
The class uses uv and heavily recommends using einops, both of which I find awesome. Hydra is used by the teaching team but not so necessary
Workload
The workload was very high (see the Carta reviews) but doable. Basically there were four (4) big assignments (Basics, Systems, Data, Alignment and Reasoning RL) spaced two weeks apart and a small one (Scaling) between Systems and Data. You have six (6) late days total, up to three (3) per assignment. I used two late days for Systems, and three in the end for RL to use them up.
In general I would spend an entire weekend (very high utilization of waking hours) + Monday working on an assignment, which were all supposed to be due on Tuesdays. However problems with the GPU cluster made Assignment 2 due on a Wednesday, and both Assignment 4 and 5 due on Fridays (free extensions).
Speaking of the cluster, we had a GPU cluster with a lot of H100s sponsored by Together AI. Jobs were submitted using Slurm. We did not need to write preemptible code, and usage never got bad enough that one would not get a GPU for hours (though the QoS was dialed back drastically that after Assignment 2 we would only have 1 GPU per job). I am really thankful for all the GPU time, and Marcel on the CA team was amazing at both ML and managing the cluster and helping people.
Lectures
There were 19 total lectures. Tatsu used slides and usually covered new ideas & research, while Percy usually went code-level and used “executable lectures” (like this) that are Python programs whose execution you can step through like in a debugger. It reminds me more of literate programming in orgmode than Jupyter notebooks due to the fact that Percy’s text and images are grouped under individual functions, and stepping up and down the stack feels like navigating org headings in a structured manner.
I group the lectures into the following sections by themes:
Introduction & Model Architecture
Overview, tokenization (Percy)
PyTorch, resource accounting (Percy)
Architectures, hyperparameters (Tatsu)
Mixture of experts (Tatsu)
These lectures were very nice intros, and Tatsu reviewed basically all current open-source models for their architecture choices

Systems & GPUs
GPUs (Tatsu)
Kernels, Triton (Tatsu)
Parallelism (Tatsu)
Parallelism (Percy)
These lectures cover a lot; one doesn’t become an expert in writing CUDA or pipeline parallelism just from them. The assignments you to use collective operations in torch.dist and write some Triton kernels.
Scaling Laws, Data
Scaling laws (Tatsu)
Inference (Percy)
Scaling laws (Tatsu)
Evaluation (Percy)
Data (Percy)
Data (Percy)
These lectures had the least amount of code or implementation but are again great overviews of the topics. Even though we did not need to implement efficient inference for the assignments, the inference lecture was amazing.
RL & Alignment
Alignment - SFT/RLHF (Tatsu)
Alignment - RL (Tatsu)
Alignment - RL (Percy)
Tatsu covered SFT, RLHF (PPO), DPO, GRPO, and specific variants & case studies. Percy’s executable lecture on policy gradient mechanics & GRPO was really cool and worth stepping through.
Guest Lectures
Guest Lecture on Qwen 3 by Junyang Lin
Guest lecture on Llama 3 by Mike Lewis
Overall all lectures were great and I didn’t miss a single one, which I rarely get to say.
Assignments
All assignments had unit tests to verify the correctness of certain interfaces you are asked to implement. While these sparse rewards do mean you can brute-force a little at times, you can definitely pass the test cases and still be intractably slow or subtly wrong that that things crash when you integrate or training is buggy.
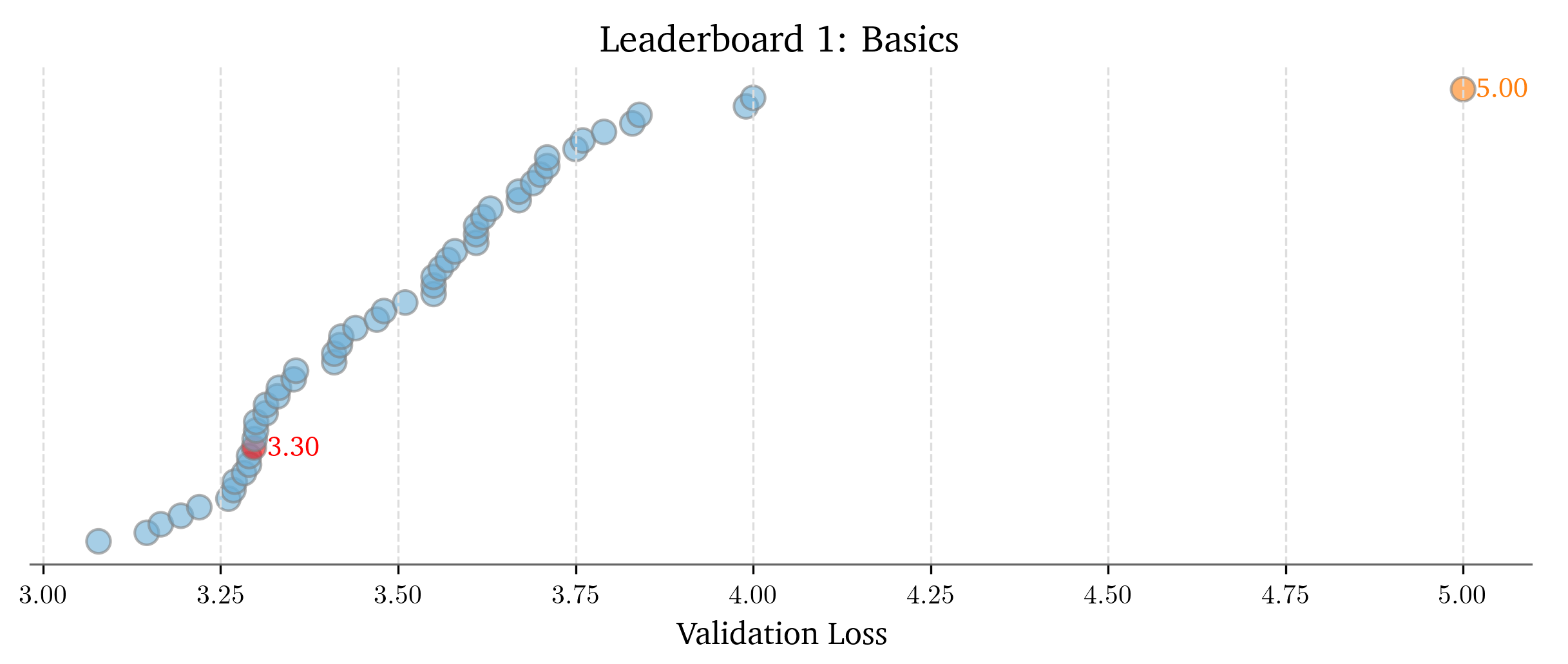
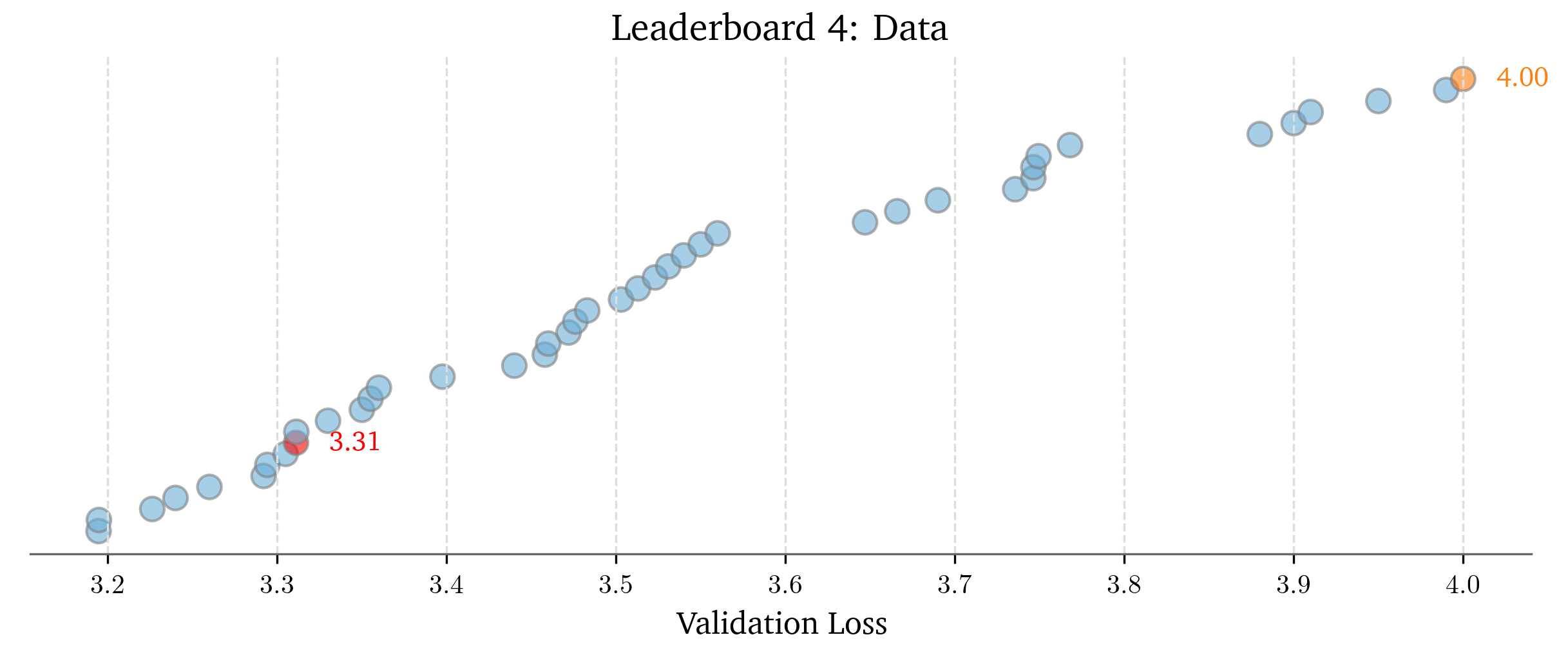
There were mandatory leaderboards for Assignments 1, 4, and 5, and here’s how many submissions there were (my submission in red):
Basics Leaderboard: 55 submissions
Data Leaderboard: 41 submissions
Alignment Leaderboard: 47 submissions
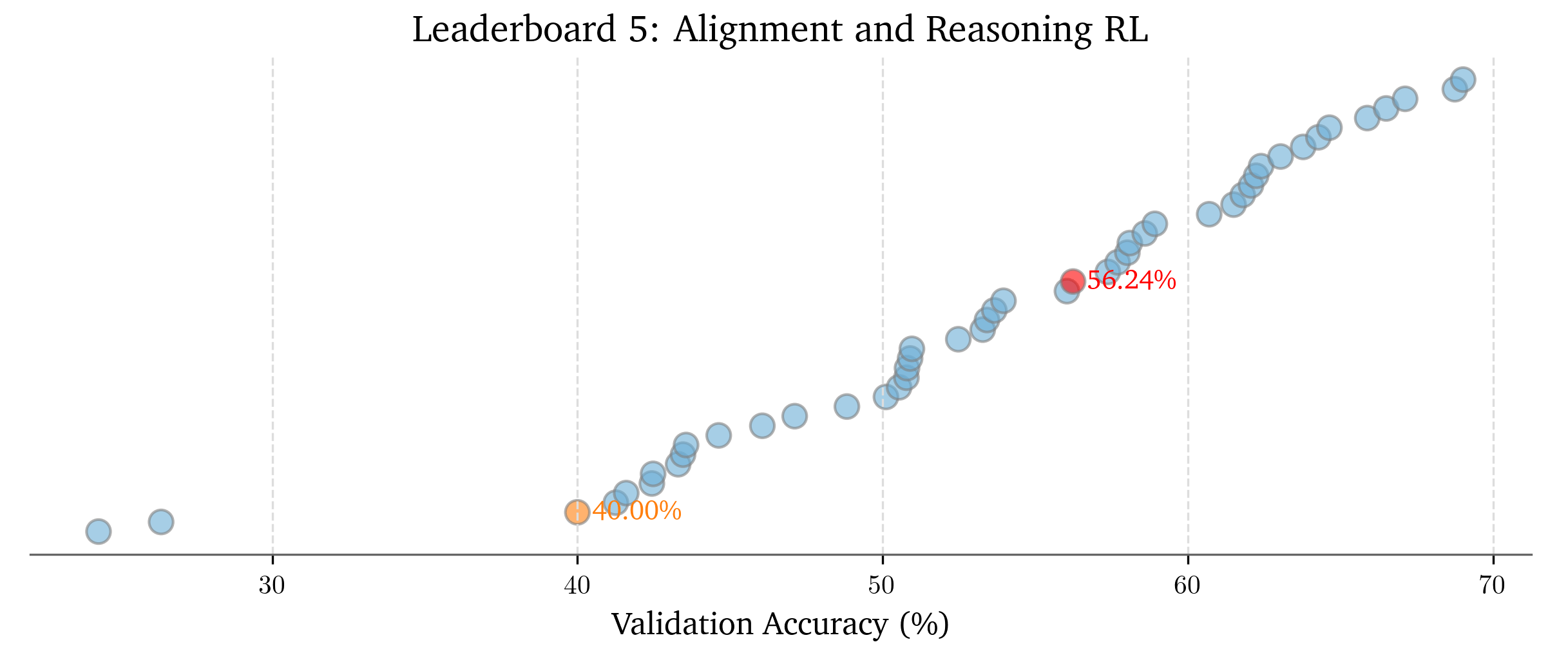
(I seem to have dropped the ball harder on this one, but to my defense I didn’t know submissions made after the late deadline would still be merged)
Basics
Basics was a weeder and quite intense. A lot of people seem to have dropped the class if they could not build a good tokenizer and time was running out for implementing a working transformer LM by the first assignment.
A high level spec for the BPE tokenizer was provided, though the teaching team eventually gave a detailed description of a reference implementation on Slack after too many people had problems. The tokenizer was definitely no more difficult than something from a typical systems class.
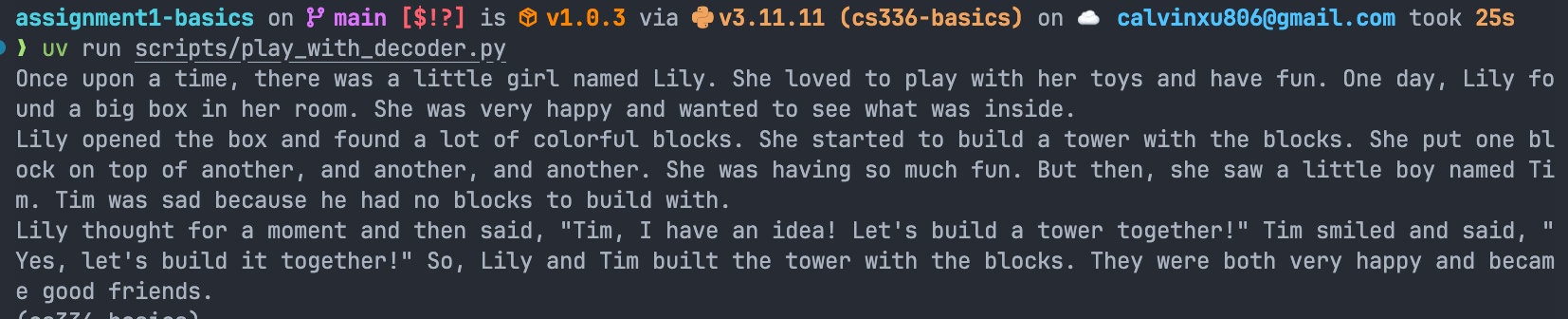
For implementing the transformer LM, it’s not hard if you have played with nanoGPT or minGPT. I used the opportunity to familiarize myself with einops. Note that this is basically the last assignment you can do on non-Nvidia hardware / not using CUDA / not using the cluster.
first words from my LM trained on my laptop with MPS:
Systems
I remember this one being the most work for me; it felt immensely like preparing data and figures for publication. You need to benchmark and analyze a lot of experiments & everything you implement, which include FlashAttention 2 forward pass as (both PyTorch and Triton kernel), some different DDP strategies, among others. Nsight Systems is needed for a number of the benchmarks, and make sure to start early so you have enough GPUs for the parallelism experiments.
My progress tracking sheet; time estimates by o4-mini-high (asked to be on the pessimistic side)
![]()
Scaling
This one was more or less a freebie. The main part of the assignment was fitting a scaling law on a fixed FLOPs budget, where you can query a course API for the final training loss of any training run you configure instantly. Apparently real losses were reported using data measured in actual runs and tree-based interpolation, though the data points were sparse in higher FLOPs regimes and interpolation can go bad. You win by having the best prediction for the actual expensive training run.
The intro was fire ngl:

Data
This one had minimal required implementation pieces (mostly writing some regex, Gopher quality rules, minhashing & LSH), and is centered around filtering for a good subset of Common Crawl data that achieves the lowest validation loss during two-hour training. Since you are told what validation data is (C4 EN, 4215 examples), you can overfit as much as you want on it.
The primary difficulty with this assignment was that CPU usage went way up. We were originally supposed to all get 64 CPUs across all jobs, but that was slashed to 8 for QoS, such that it took multiple hours to do one pass over the provided Common Crawl data. These are some specific suggestions from me:
Use your local compute & storage for the data preparation part of the assignment in case of QoS. For tokenization it was faster to transfer over 30 GB via scp, do it on my laptop, then transfer it back to the cluster
Decode and check the official tokenized validation data to match the format & usage of special tokens exactly when encoding training data
Don’t spend too much time on initially training the fasttext quality classifier like I did (i.e., I scraped over 200k pages for it after reading some comments on Slack). You may realize for the leaderboard you’d want something different
The data loader was in random order, so no need to think about scheduling the data
Remember
awkandgawkare your friend
anecdotal: I sometimes somehow got interactive sessions that had nproc=64 and did not time out for no particular reason that helped a lot, particularly with tokenizing the data
Alignment and Reasoning RL
This one was fun (more fun than watching curve go down). You implement SFT, GRPO, and do a lot of ablations and analysis to observe things like the length bias first hand. It is a great intro to getting into the nitty gritty of RL w/ LLMs, such as loading PyTorch policy into & doing rollouts with vLLM. The cluster was unfortunately still oversubscribed around this time and running out of disk from the previous assignment, resulting in brief downtime and that the QoS became one GPU instead of two. Things just took longer, but ultimately it was great to see RL actually work and a great ending to the course.
In Conclusion
This is a great class! As alternatives you can follow something like MiniTorch or just nanoGPT, but per above a diverse range of topics outside model architecture & systems are covered, plus cutting-edge research progress. All materials are available online too.
I think this is the best class if you got tired of filling in a few lines in a Jupyter notebook at a time. Not so theory heavy, and I think you should try building something smaller & more elegant (like VAEs) from scratch to see how much you would like the idea of this class.
Bonus:
Percy’s & Tatsu’s office hours were great
You get a cool shirt in the end (back side):

(there should to be things inside the attention blocks, but something with the stencils went wrong, and now they are just black / white boxes, which is better than the other jokes that tried hard)
